Introduction
GPU, Graphics Processing Unit, is initially designed to accelerate image rendering such as video games. For its high performance at parallel computation, it has become a great processor for accelerating DL/ML training.
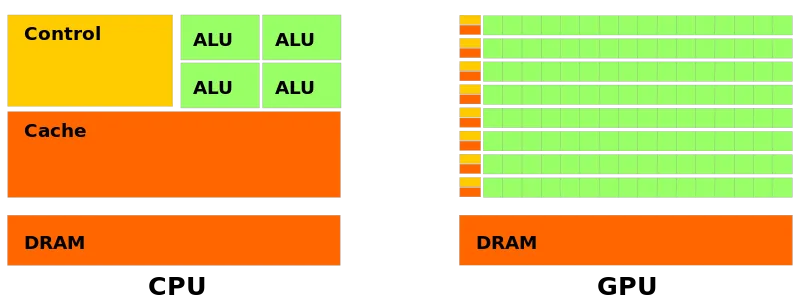
Unlike CPU, GPU consists of numerous computational units, long pipeline and a video memory, which determines its advantages in parallel computation and disadvantages in complex control logic handling.
Computational units(cores)
In total, computational units of CPU are fast but few, while that of GPU are slow but numerous. The fastness of CPU is based on its high frequency and smart calculation. Here, smartness is reflected by its out-of-order executions, multiple branch prediction and etc.
But GPU can only handle some easy linear work like fmuladd instructions. In fact, except small scalar float, modern GPU can perform operations on more complicated type like tensor(tensor core).
SIMD not only exist in CPU, but also in GPU. Same operation, but different data, such feature make GPU fast in parallel work like matrix multiplication.
Memory
Memory of GPU is much tinier than CPU's. And cache in GPU has some difference with what L1, L2 in CPU do.
For reduce in parallel computation, it requires multiple cores share memory. But it's hard and expensive for thousands of core share one memory segment. So we divide different types of cores into multiple groups, called Streaming Multiprocessors;
There are INT32, FP32 and other types of SM in GPU. So how they cooperate?
In TU102. every 4 SMs share a shared segment of L1 cache, and all cores share L2 cache. Like CPU, after missing data in L1, core will try to hit L2, and then GMEM. To note, how L1 is shared is controlled by software or programmer, not hardware. But L2 and GMEM is controlled by hardware. Besides, cores can also share data in registers.
The basic idea is that every thread holds a register to keep temporary result and every register can only be visited by one consistent thread(or by same wrap/group).