1. Introduction
It's always hard to write code for parallel programs, and harder to write correct and fast code on GPU. Writing a simple CUDA Renderer would be an opportunity to practice.
In this article, the CUDA version is 12.1, the GPU is RTX 3090.
2. Task
Given the positions, RGBs and other information of a bunch of circles(may be transparent), you need to implement a fastest and correct render function for these circles you can.
If we don't care about the order of circles, it would be just an easy programming assignment. However, the circles can be transparent, that is, we need to blend every pixel based on the original color in that pixel. The render uses the following math: \[C_{new} = \alpha C_{i} + (1 - \alpha) C_{old}\] Such composition is not commutative, so it's important to draw the pixel following the correct order:
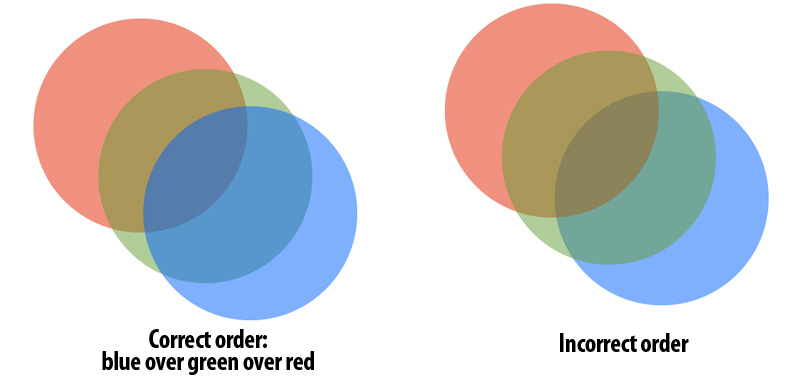
3. Extract Parallelism (Offical) (Prefix-Sum)
So how can we make it parallel to render? An basic insight is that we could draw every pixel independently. Since nothing is required to share between pixels, we could render a pixel in the order of circles. The kernel function is just like:
1 | void renderPixel() { |
Another insight is that, we could scan a bunch of circles once to see whether this pixel is in the circle. But how can we synchronize and reduce the result from one scan?
Parallel prefix-sum algorithm makes sense here. Every thread in scan compute whether the pixel intersects one circle, then put the result in a boolean array incircle. By computing the prefix-sum of incircle parallelly, we get an result array indexes and the count of intersected circles. indexes[i] is the number of intersected circle son top of which ith circle lies. Knowing the indexes of circles that intersect, we could parallelize the renderer further(pseudocode):
1 | void renderPixel() { |
This solution looks generally good, but it cannot reach full points on my machine. I guess the cause is that, it's expensive to spawn a large amout of threads and synchronize them, especially there is just single circle in the scene.
To prevent synchronization and unnecessary threads, I propose another method to solve it.
4. Extract Parallelism (Split Space into Boxes)
Confronted with this task, the first thing occurred to me is quad-tree, which splits space into multiple small boxes dynamically, so that we only need to check whether entities in the small box intersect. In this way, we avoid computing intersection for every entity in the whole space. Such technique is often applied in game engine.
In the solution above, to render a pixel, we need to check all circles in the scene and see whether they intersect the current pixel. That's UNNECESSARY indeed. If we split the scene into uninterleaved boxes and compute the intersected circles in each box, and only try to draw the circles in the same box with that of the pixel parallelly, many unnecessary drawCircle calls could be avoided. With such intuition, I handicraft a fast CUDA renderer by splitting the 2D scene space. In this section, I will show how I optimize my renderer step by step.
4.1 Split Space on CPU
Based on MISS principle in software engineering, We'd better write correct code first. And then consider improving it.
A trivial solution on CPU is to split the space into equally-sized boxes, computing intersection between circles and boxes, and copy the results to GPU.
Basic procedure is like: 1
2
3
4
5
6
7
8
9
10
11allocate "circlesInBox" array
for every circle
check which boxes overlap with the circle
for overlapped boxes
put this circle index into circlesInBox[box]
transfer data from CPU to GPU
for every box
kernel_render_on_box<<<...>>>(box)
This method won the score of 20 on my machine.
When I analyzed the performance bottleneck, my first thought was that cudaMalloc and the cudaMemcpy between host and device are slow and costly. Even worse, cudaMemcpy leads to all threads on device to synchronize, it's really, really slow. Meanwhile it's also expensive to spawn the kernel calls separately.
Let's prove the inference above. Run nsys on the renderer, and see the profiling information: 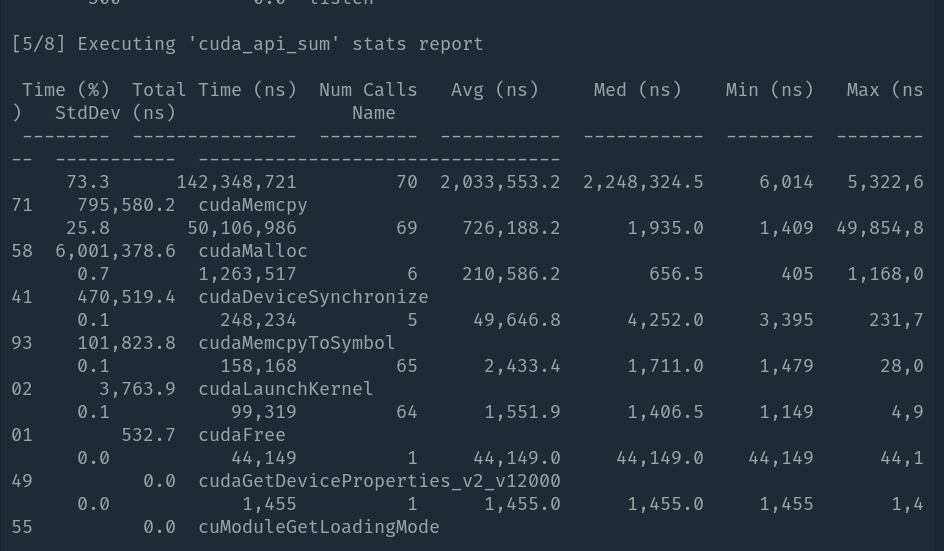
Obivously, the latency of cudaMalloc and cudaMemcpy is a big overhead. Let's resolve this first!
4.2 Copy the memory asynchronously
The first thing I did is to replace cudaMemcpy with cudaMemcpyAsync. Though the document warns:
- If pageable memory must first be staged to pinned memory, the driver may synchronize with the stream and stage the copy into pinned memory.
But reality is that cudaMemcpyAsync always runs asynchronously on my machine. This helps with reducing/hiding latency:
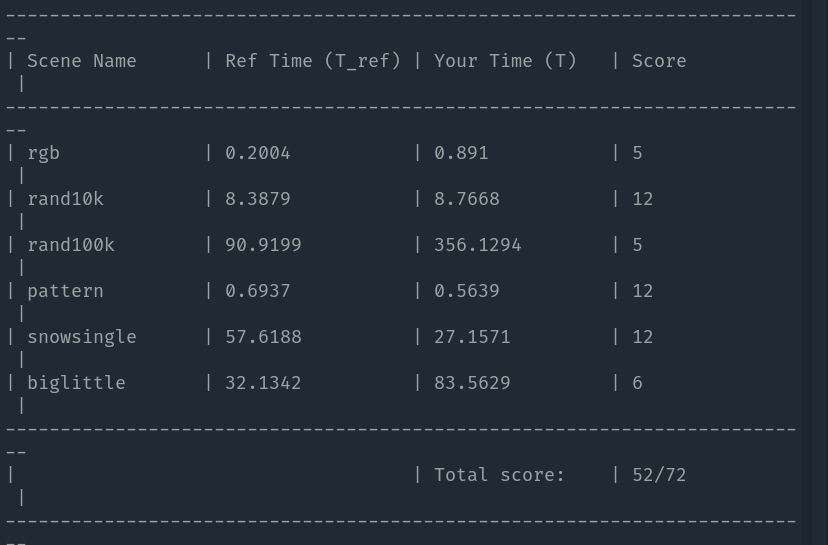
This method overperforms cpu-ref in terms of speed for some tests. But it's not fast enough. Obviously, for rand100k and biglittle tests, we are slow. Let's profile again on rand100k test:
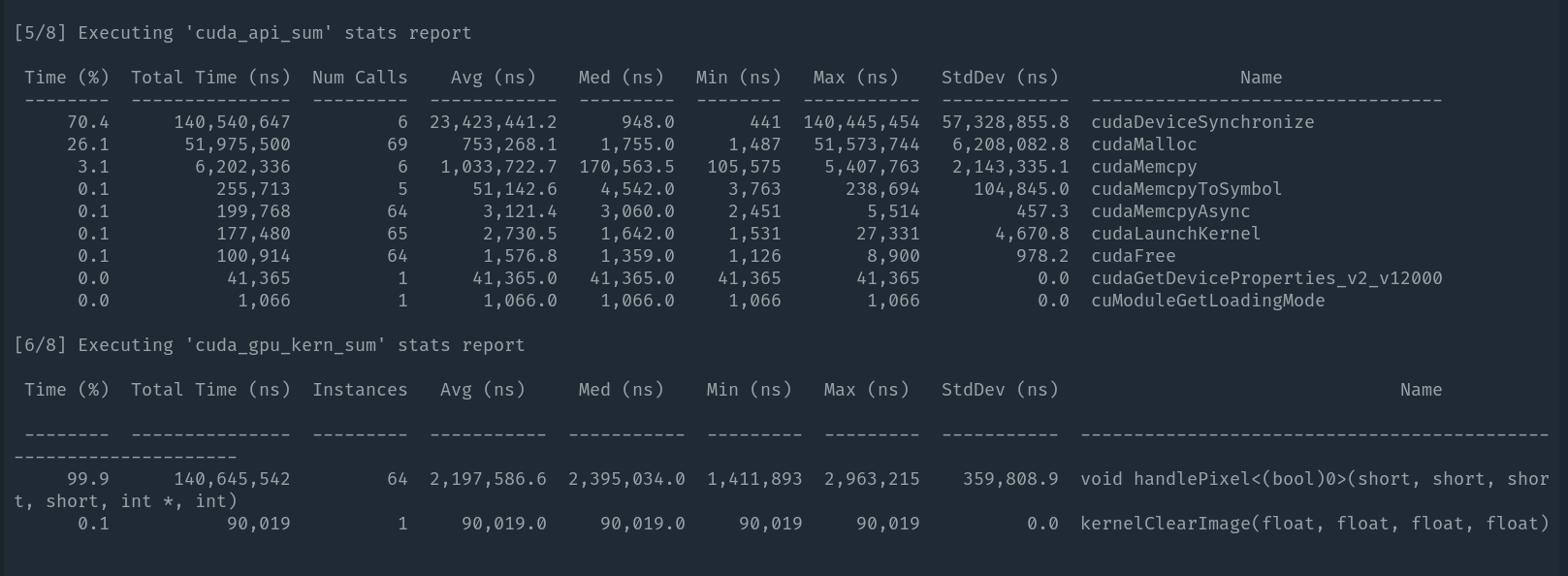
cudaMalloc still plays a role as an overhead here. Further optimization needs parallelized splitting on GPU, preventing data allocations/moves from host to device.
4.2 Split Space on GPU
The split method on CPU focus on circles firstly, instead of boxes. On GPU, it's easier to focus on independent boxes parallelly. So the GPU splitting kernel is like: 1
2
3
4
5
6void findCirclesInBox() {
Box mybox = assignBox(thread index);
for every circle
if circle intersect mybox
addCircle(mybox, circle)
}
Greatly, this improve won the score of 61. Now, the CUDA renderer with splitted space could compete the offical solution!
4.3 Reduce Memory Access to Global Memory
Traditional compilers reduce unnecessary memory access to register, which enhance performance of application especially when extracting memory access in loops (AFAIK, LLVM always perform this type of optimization in LICM). But for CUDA, it's impossible to do such optimization without knowing whether the memory position is accessed by other threads.
This is a snippet from kernel render function for every pixel: 1
2
3
4
5
6float4* img = ...; // A pointer pointing to a part of global variable
for (int i = 0; i < numInBox; i++) {
int circleIndex3 = 3 * circleIndexes[i];
float3 p = position[circleIndex3];
shade(circleIndexes[i], ... , img); // "shade" reads and writes "img"
}
Global memory is a slow memory region in GPU. My intuition is to promote it to register:
1 | float4* img = ...; // A pointer pointing to a part of global variable |
Surprisingly, the minor change make the renderer defeat render_ref completely and win score of 72 sometimes. Hard to imagine the impact it brought.
Take a look at the original NVPTX assembly by cuobjdump -ptx: 1
2
3
4
5
6
7
8
9
10loop:
...
ld.global.v4.f32 {%f65, %f66, %f67, %f68}, [%rd4];
...
st.global.v4.f32 [%rd4], {%f78, %f77, %f76, %f79};
...
@%p4 bra $loop
loopexit:
...
And the assembly after change: 1
2
3
4
5
6
7
8
9ld.global.v4.f32 {%f65, %f66, %f67, %f68}, [%rd4];
loop:
...
@%p4 bra $loop
loopexit:
st.global.v4.f32 [%rd4], {%f78, %f77, %f76, %f79};
...
Similarly, compiler cannot determine the equivalence of two loads of identical memory address. I imitated CSE (common sub-expression elimination) technique of compiler optimization, replace circleIndexes[i] with a common variable: 1
2
3
4
5
6
7
8float4* img = ...; // A pointer pointing to a part of global variable
float4 imgTmp = *img; // In register
for (int i = 0; i < numInBox; i++) {
int circleIndex3 = 3 * circleIndexes[i];
float3 p = position[circleIndex3];
shade(circleIndexes[i], ... , &imgTmp); // "shade" now reads and writes a register
}
*img = imgTmp;1
2
3
4
5
6
7
8
9float4* img = ...; // A pointer pointing to a part of global variable
float4 imgTmp = *img; // In register
for (int i = 0; i < numInBox; i++) {
int index = circleindexes[i];
int circleIndex3 = 3 * index;
float3 p = position[circleIndex3];
shade(index, ... , &imgTmp); // "shade" now reads and writes a register
}
*img = imgTmp;
But wait... Whether can we utilize parallelism of circles inside a box with shared memory and prefix-sum?
The result is BAD. By default, I split the scene into 128x128 boxes. And in most cases, the number of circles inside a box is less than 1000. Synchronizing a large bunch threads in a scan become a big overhead. In simple rgb scene, it runs for even over 10ms.
Also, I tried to do the prefix-sum algorithm in warp level. I guess warp-level synchronization primitives are cheaper. But the result is BAD too.
I think a better solution is to build a quad-tree parallelly and compute in tree node. Maybe I will implement it in my free time.
5. Final Result
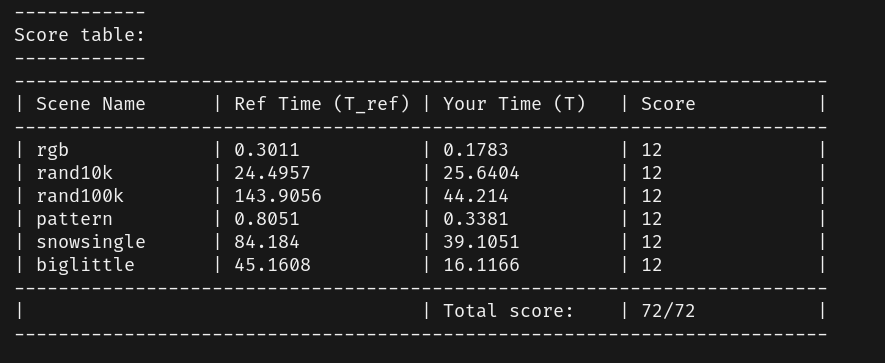
6. Some inspiration
Threads in a warp always synchronize(converge). The GPU scheduler schedule by warps(instead of thread). Since GPU is always SIMT/SIMD, all threads in a warp execute identical instruction at a time. If threads in warp diverge, warp will go through every path. Thus warp must wait for one path even though other threads are inactive on this path. Anyway, if two threads in a warp wait for a spinning lock, that would be a dead lock.
Parallelism is not always better. Amdahl's formula proves it: \[S = \frac{1}{1 - a + \frac{a}{n}}\] And the overhead of parallelism would make it slower.
Memory Access should be considered seriously.
Global memory, constant memory, register(on chip), local memory(on chip) differ in terms of speed and storage. To prevent memory bound, we should pick suitable memory region to handle data.