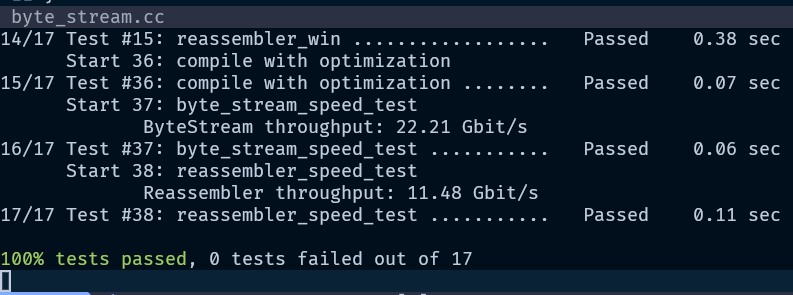
The projection of \(\boldsymbol{b}\) onto a subspace \(C(A)\) is computed by:
\[
\boldsymbol{p} = P\boldsymbol{b}
\]
where \(P\) is called Projection Matrix. The reason for multiplying a matrix is based on how the projection is computed.
Here is the reasoning steps:
Let's image that there is \(\boldsymbol{b}\) projecting onto a plane \(C(A)\), producing projection \(\boldsymbol{p}\). Then \(\boldsymbol{p}\) is in \(C(A)\), which could be expressed as \(A\boldsymbol{\hat{x}}\). Our goal is to get \(\boldsymbol{\hat{x}}\).
Let \(\boldsymbol{e = b - A\hat{x}}\) be the error vector , only when \(\boldsymbol{e}\) is perpendicular to the subspace, can we say \(\boldsymbol{p = b - e}\) is projection.
Since \(\boldsymbol{e}\) is perpendicular to \(C(A)\), we can get: \[A^T(\boldsymbol{b}-A\boldsymbol{\hat{x}}) = \boldsymbol{0}\] or \[A^TA\boldsymbol{\hat{x}} = A^T\boldsymbol{b}\]
The symmetric matrix \(A^TA\) is invertible if and only if \(\boldsymbol{a's}\) in \(A\) are independent. Then, \[\boldsymbol{p} = A\boldsymbol{\hat{x}}=A(A^TA)^{-1}A^T\boldsymbol{b}\]
Here \(A(A^TA)^{-1}A^T\) is a matrix, we name it Projection Matrix. You might try to split \((A^TA)^{-1}\) into \(A^{-1}(A^{T})^{-1}\), however when \(A\) is rectangular, it has no inverse.
Or when \(A\) is invertible, \(N(A), N(A^T)\) contains only zero vector, where \(A^T\boldsymbol{e} = 0 \rightarrow \boldsymbol{e=0, b=p}\) itself, \(P = \boldsymbol{I}\) satisfies it well.
Why the symmetric matrix \(A^TA\) is invertible if and only if \(\boldsymbol{a's}\) in \(A\) are independent?
\[A^TAx = 0 \Longleftrightarrow Ax = 0\]
Thus \(A^TA\) has the same nullspace with \(A\). \(A\) is invertible, if and only if \(A^TA\) is invertible.